Calibration
How well your confidence tracks reality. The meta-skill underneath probabilistic thinking, and the one most thoughtful people are surprisingly bad at, until they train themselves out of it.
In the early 2000s, the political scientist Philip Tetlock published the results of a study so unflattering to his own profession that several of its participants reportedly stopped speaking to him. Over the course of two decades, Tetlock had asked nearly 300 expert forecasters (political scientists, intelligence analysts, journalists, advisors) to make over 80,000 predictions about geopolitical and economic events. He then waited, sometimes years, to see what actually happened. The results were brutal. The average expert performed only slightly better than random guessing, and the most famous, most-quoted experts, the ones with the strongest media presence and the most confident predictions, performed worse than the less-famous ones. They weren't more right. They were more wrong, more often, while sounding more sure.
Tetlock's findings, published in his 2005 book Expert Political Judgment, became one of the most cited critiques of expertise ever produced. But buried in the data was something more interesting than the headline. A small subset of forecasters performed dramatically better than the rest, not because they were smarter or better-informed, but because they had a specific cognitive habit the others lacked. They knew how confident to be. When they said they were 70% sure, they were right about 70% of the time. When they said they were 90% sure, they were right about 90% of the time. They didn't always make better predictions; they made better-calibrated ones, and over thousands of forecasts that small advantage compounded into a measurable, replicable difference. Tetlock named these forecasters "superforecasters," and the skill they shared has a name in statistics that's been around for over a century: calibration.
Calibration is the meta-skill of probabilistic thinking. Base rates tell you the prior frequency. Bayes' Rule tells you how to update it. Expected value tells you how to choose. But all three frameworks assume something they cannot themselves provide: that the probabilities you're working with are actually accurate. If you say you're 90% confident in something but you're actually right only 60% of the time at that confidence level, every downstream calculation built on your probabilities is corrupted at the source. The math doesn't fix bad inputs; it propagates them. Calibration is the audit on the inputs.
Most people are badly calibrated, and most people don't know it. Even more uncomfortably, calibration is largely orthogonal to intelligence and education. Being smart doesn't make you well-calibrated, and in some specific ways it can make you worse. The good news is that calibration is trainable. The world's best forecasters (weather meteorologists, professional gamblers, prediction-market traders, superforecasters) all developed it through a remarkably similar process. This essay is about what that process looks like, why it works, and where it doesn't.
What calibration actually means
Calibration is a specific technical claim, not a vague disposition. You are well-calibrated if, of the predictions you make at a given confidence level, that fraction turn out to be correct. If you said you were 80% sure of a hundred different things, about 80 of them should turn out to be true. If only 50 of them did, you were systematically overconfident. If 95 of them did, you were under-confident. The percentage you assign to your confidence is supposed to be the long-run frequency of being right at that level, and calibration measures how well it actually corresponds.
This is a much stronger claim than "I'm about right most of the time." It says that when you generate a probability, that probability should mean exactly what it says it means. A weather forecaster who says "70% chance of rain" is well-calibrated if it actually rains on about 70% of the days they make that forecast, not 50% and not 90%. A startup investor who says "I'm 30% confident this will hit our return target" is well-calibrated if about 30% of investments at that confidence level actually do. A doctor who says "I'm 95% sure it's not cancer" is well-calibrated if about 5% of those reassurances turn out, in fact, to be cancer. The number is a promise, and calibration is whether the promise gets kept.
The simplest definition
Calibration is the property that your stated confidence equals the actual long-run frequency of being right. "70% sure" should mean right 70% of the time. Most people's "70% sure" actually means right 50% of the time. Closing that gap is the entire skill.
One thing this definition implies is that calibration is meaningful only across many predictions. You cannot be calibrated on a single forecast. The prediction either happens or it doesn't, and a single outcome doesn't tell you whether your 70% was a 70% or a 30%. Calibration is a property of a set of predictions made at various confidence levels, evaluated over time. This is partly why so few people are well-calibrated in their daily lives: they never collect the data on themselves that would let them measure it. Without the feedback loop, the skill can't develop, because the skill is the loop.
The calibration curve
The clearest visualization of calibration is a chart that compares stated confidence levels to actual hit rates. A perfectly calibrated forecaster's predictions form a straight diagonal line. When they say 50%, they're right 50% of the time; when they say 90%, they're right 90% of the time. Real human forecasters almost always deviate from this line in a characteristic way: they are overconfident at the high end, claiming 95% confidence on predictions that turn out to be right only 80% of the time, and sometimes under-confident at the low end, treating things they're sure won't happen as if they had a 30% chance.
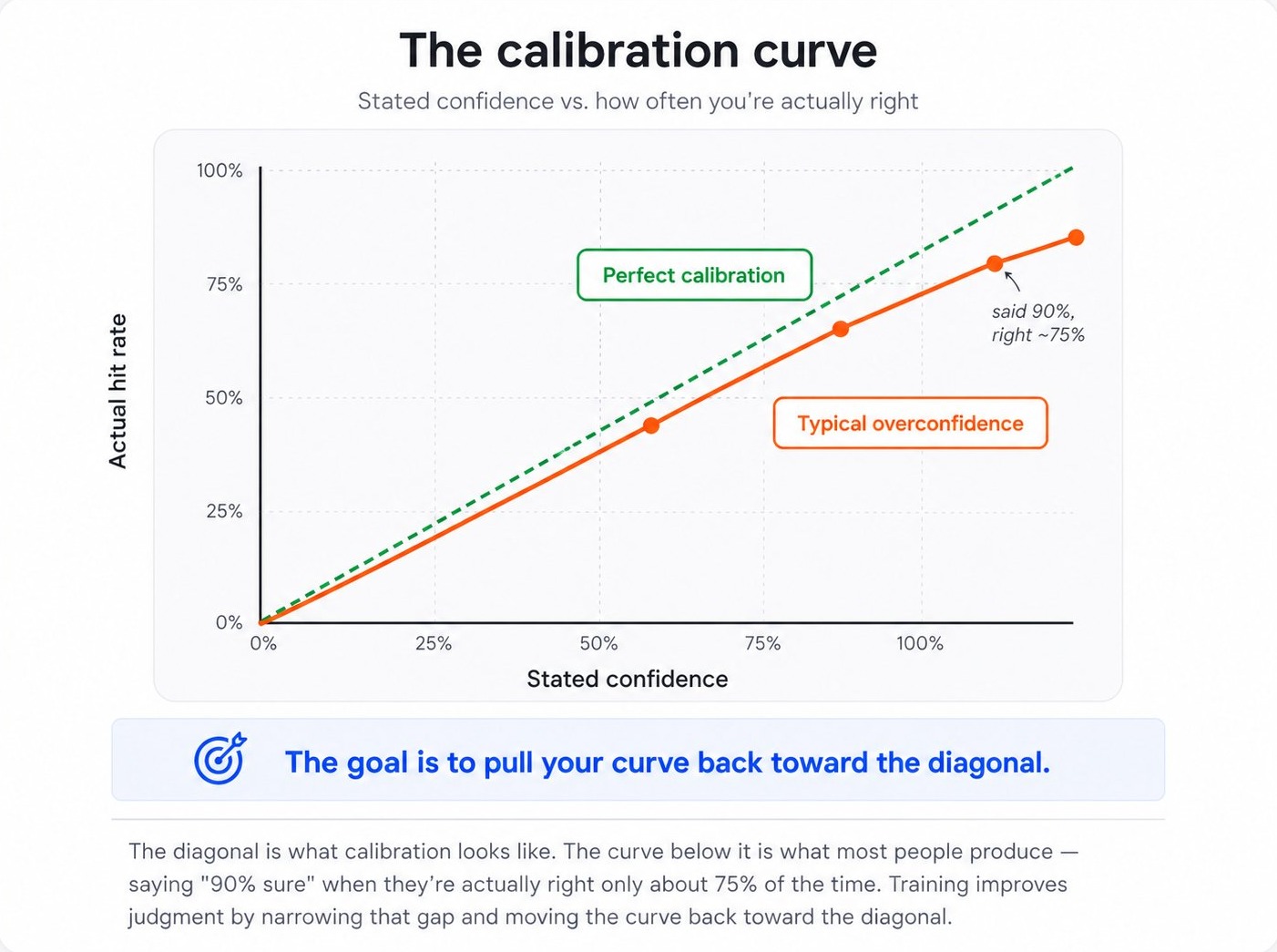
The shape of the typical overconfidence curve isn't random. It's reliable across studies, demographics, and domains. The deviation from the diagonal is largest at the highest confidence levels. People who claim 99% certainty are wrong far more often than 1% of the time. People who claim 50% certainty are about right at 50% (which makes sense; 50% is a confession of ignorance, not a confident claim). The miscalibration is concentrated at exactly the place where it matters most: the predictions we feel surest about.
This pattern has been replicated dozens of times: in financial analysts, doctors making diagnostic predictions, lawyers estimating case outcomes, executives forecasting business results, programmers estimating project timelines. The specific shape of the curve varies a little by profession, but the direction almost never does: people are systematically more confident than the world warrants. The shift toward calibration always involves moving claimed confidence levels downward, especially at the high end.
Calibration vs. accuracy: a critical distinction
One of the most important things to understand about calibration is that it's not the same as being right. You can be calibrated without being right often, and you can be right often without being calibrated. The two are orthogonal dimensions, and most people conflate them.

The four quadrants of this matrix illuminate a lot. The "confidently wrong" quadrant (bottom-left) is where most loud public commentators live, because being confident on television is rewarded regardless of accuracy. The "honest about uncertainty" quadrant (top-left) is where good weather forecasters live, because the domain is hard but they've learned to say "30% chance of rain" and have it actually rain 30% of the time. They aren't right often, in the sense of usually predicting rain when it occurs, but their probabilities mean what they say they mean. The top-right is the rare ideal: forecasters who are both calibrated and accurate, because they know enough about the domain to make confident predictions and well-calibrated enough to know when not to be.
The reason this distinction matters so much is that good decision-making requires both. A perfectly calibrated forecaster who only ever says "50% on everything" is technically calibrated but useless. Their predictions don't help anyone choose between options. An accurate forecaster who's wildly overconfident might still make good calls but consistently mis-sizes their bets, betting too big when their confidence outpaces their actual hit rate. The aim is to be calibrated and accurate, making sharp predictions whose confidence levels can be trusted. Most "expert" critique is really critique of the bottom-left quadrant: confident, wrong, public, and unaccountable. The fix isn't to be less confident in everything. It's to know when to be confident, which is exactly what calibration measures.
The Brier score: keeping yourself honest
The standard mathematical tool for measuring calibration is called the Brier score, named after the meteorologist Glenn Brier who proposed it in 1950 as a way to score the quality of probabilistic weather forecasts. The Brier score punishes both overconfidence and under-confidence simultaneously, and over many predictions it produces a single number that captures how well your confidence matches reality.
The math is simple: for each forecast, you take the squared difference between your stated probability (between 0 and 1) and the actual outcome (1 if it happened, 0 if it didn't). Then you average those squared differences across all your forecasts. A Brier score of 0 is perfect; 0.25 is what you'd get from always saying 50%; numbers above 0.25 mean you're doing worse than random guessing. Lower is better, and the score has the elegant property of incentivizing honesty. If you genuinely believe the probability of an event is 70%, the Brier score is minimized when you actually report 70%, not 90% or 50%. Inflating or deflating your stated confidence makes your score worse.
This last property is what makes the Brier score (and similar "proper scoring rules") so valuable. They are designed so that the only way to game them is to actually report your true beliefs. You cannot get a better score by sounding more confident than you are, by hedging strategically, or by claiming to know things you don't. The math forces honesty in a way that conversation alone cannot. This is why competitive forecasting tournaments, prediction markets, and professional weather services all rely on Brier scores or close variants. They create a feedback environment where accurate self-knowledge is the only winning strategy.
Two forecasters, same predictions
Forecaster A and Forecaster B both make 100 binary predictions. Both get 70 of them right. But A claims 95% confidence on every prediction, while B claims 70%.
A's Brier score: 0.30 × 0.95² for the 30 wrong predictions + 0.70 × 0.05² for the 70 right ones ≈ 0.272. B's Brier score: 0.30 × 0.70² + 0.70 × 0.30² ≈ 0.210. B has the better score even though both got the same hit rate, because B's confidence matched their actual performance. The math rewards calibration directly.
You don't have to use the formal Brier score to benefit from this insight. The principle it captures is more general: your stated confidence is being evaluated against reality whether you're keeping score or not. Every time you say "I'm 90% sure" and turn out to be wrong, that's a small Brier-score hit your reputation takes, and people around you are tracking it informally even when you aren't. Being a person whose stated confidence matches reality is one of the rarer and more valuable forms of professional credibility, and most people are unaware that they're systematically eroding it through habitual overconfidence.
Why most people are miscalibrated
Calibration failures aren't random. They cluster around specific patterns, and understanding them helps explain why even smart people produce poorly-calibrated forecasts and what to do about it.
Overconfidence as a default. The most pervasive miscalibration is simple overconfidence. Across virtually every domain studied, people overestimate their own accuracy. A famous 1977 study by Lichtenstein, Fischhoff, and Phillips asked subjects to answer general-knowledge questions and rate their confidence. When subjects said they were 100% confident, they were actually right about 80% of the time. When they said they were 99% confident, they were right about 85% of the time. The compression of "100%" into "actually 80%" is the canonical illustration of human overconfidence at the high end, and it's been replicated extensively since.
The "70% to 80% confidence" cluster. Most people, when asked to assign confidence levels to subjective predictions, gravitate toward a narrow range of values, usually 70% to 80% confidence. They rarely use the extremes (5% or 95%), and they rarely use 50% (which feels like an admission of ignorance). This compression isn't just stylistic. It's a calibration failure, because the actual distribution of correct answers should span a much wider range of confidence levels. Forcing yourself to use the full 0–100 scale, especially the extremes when warranted, is one of the first improvements a forecasting trainee makes.
Domain expertise paradox. Expertise often makes calibration worse, not better, in surprising ways. Experts have access to more facts, more nuance, and more reasons to be confident, but they also tend to overweight the importance of their own knowledge and underweight the genuine uncertainty in their domain. Tetlock's original study found that the most-published, most-cited experts were the least calibrated, partly because the social rewards for confident expertise outweighed the costs of being wrong (which were diffuse and forgettable). If you're recognized as an expert, the world rewards you for sounding sure even when sureness isn't warranted, and that reward shapes the confidence calibration you produce.
Status-driven boldness. In professional settings, confident-sounding predictions are a low-cost signal of competence. Saying "I'm 70% confident" sounds weaker than saying "this will definitely happen," even though the first claim is more honest. Over time, the social environment selects for boldness, and the bold are calibrated worse than the cautious because the world doesn't actually owe their confidence the certainty they claim. This is why you'll find that professional gamblers, weather forecasters, and professional poker players (people whose income depends directly on calibration) are dramatically better-calibrated than executives, pundits, and academics, whose income depends on signaling.
The hindsight bias trap. A subtler corruption of calibration is the tendency, after an event, to remember our prior confidence as having been more accurate than it was. We remember predicting things we didn't predict, and we forget the predictions we made that turned out wrong. This isn't just rewriting the past. It's actively destroying the feedback loop that calibration requires. Without honest record-keeping, the data you have on yourself is curated to show you in flattering light, and calibration training becomes impossible.
The honest test
Have you ever written down a prediction with a stated confidence level (before the event) and then checked it after? If not, you have no information about your own calibration, and your sense of how often you're right is almost certainly inflated by hindsight. The first step toward calibration is generating data the past version of you actually committed to.
The superforecasters: what they actually do
Tetlock's follow-up project to Expert Political Judgment was the Good Judgment Project (GJP), a years-long study funded by the U.S. intelligence community to find out whether forecasting could be measurably improved through training. The answer turned out to be yes, and the training that worked was surprisingly specific. The top performers, whom Tetlock called superforecasters, were not necessarily the smartest or most-credentialed participants. They were, instead, distinguished by a particular set of habits, almost all of which can be learned.
The first habit is writing predictions down with explicit confidence levels. Almost every superforecaster keeps some form of forecast log: a list of predictions with timestamps, stated probabilities, and reasoning. This isn't a journal; it's a feedback substrate. Without the written record, the calibration loop can't close. With it, every resolved prediction provides a training signal.
The second habit is updating frequently and in small increments. The bad forecasters in Tetlock's studies tended to either anchor stubbornly on initial predictions (refusing to update in the face of new information) or swing dramatically (over-updating on each new piece of news). Superforecasters update often, but always by small amounts (typically 5–10 percentage points at a time), keeping the inertia of prior reasoning while still being responsive to evidence. This is exactly the Bayesian discipline applied to real-world forecasts.
The third habit is breaking down questions into components. Asked "will Country X have a recession next year?", the average forecaster produces a single intuitive guess. The superforecaster breaks the question into sub-questions: what's the base rate of recessions in similar economies in similar years? What specific leading indicators are flashing? What policy responses are available? Each sub-question is easier to estimate, and combining them often produces a sharper, better-calibrated answer than any single intuitive guess.
The fourth habit is seeking out disconfirming information. Bad forecasters update primarily on evidence that confirms their existing view, leading to confidence escalation that exceeds what reality supports. Superforecasters explicitly look for evidence against their current best guess, and they treat the absence of disconfirming evidence as itself meaningful (because if a prediction were really 95% likely, you'd expect lots of evidence supporting it; the absence of such evidence is a Bayesian update toward lower confidence).
The fifth habit, and perhaps the most uncomfortable, is willingness to be wrong publicly. Superforecasters track their record openly, share their reasoning, and accept the social cost of being wrong on individual predictions in exchange for the long-term benefit of sharper feedback. Most professional forecasters will not do this; the social cost of being publicly wrong on a few predictions outweighs the diffuse benefit of long-term calibration improvement, and so they hedge or stay vague. The superforecasters trade in the other direction, and over thousands of forecasts the trade pays off.
How to train your calibration
The good news is that calibration is one of the most trainable cognitive skills there is. Studies of forecasting tournaments have shown that even brief training interventions (a few hours of explicit practice with feedback) can produce measurable, durable improvements in calibration scores. The basic protocol is simple, even if doing it consistently is hard.
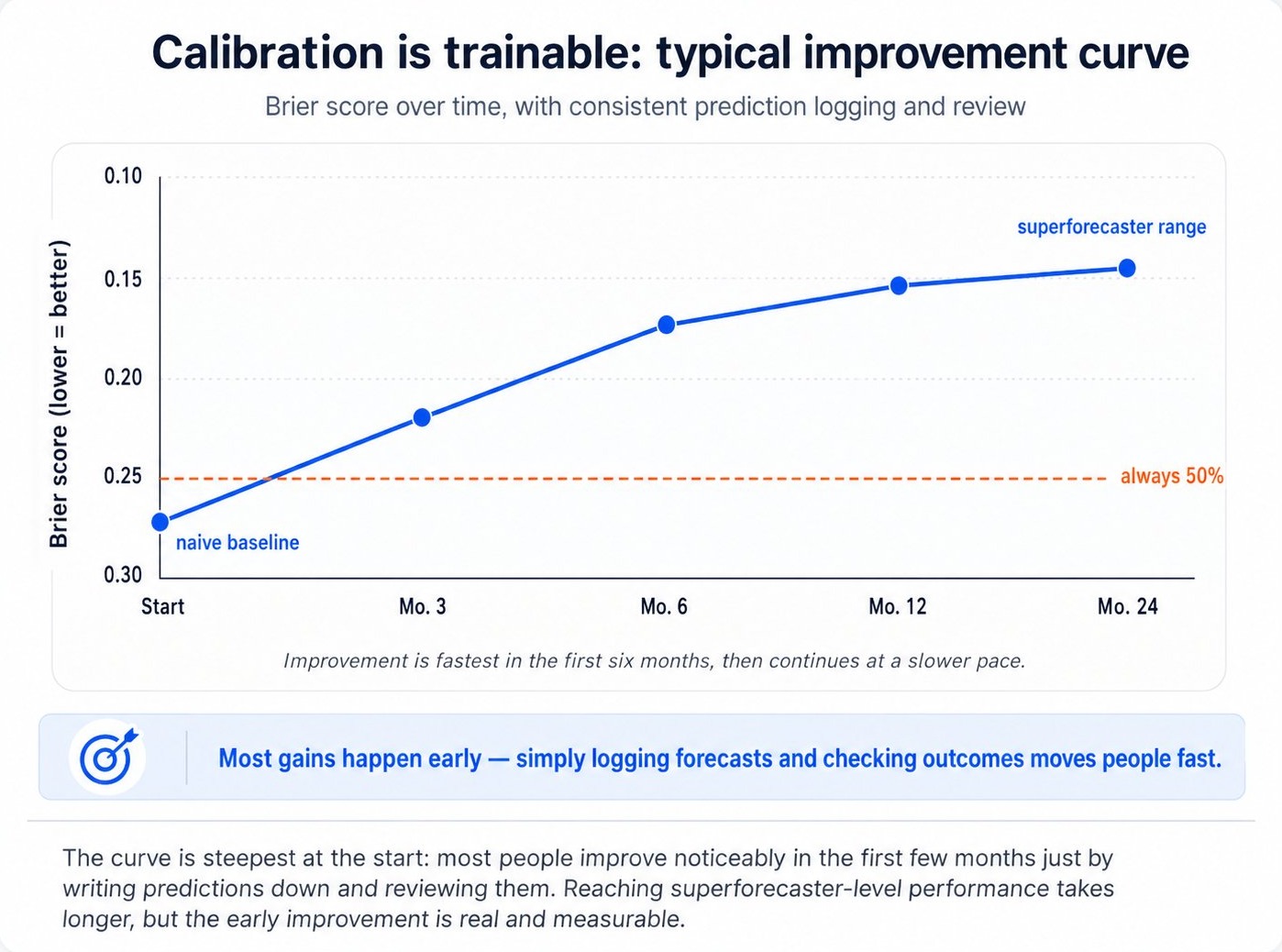
The protocol that works has five components, drawn from the Good Judgment Project and similar forecasting research:
First, make predictions in writing with explicit confidence levels. Vague predictions ("I think this will probably happen") can never be calibrated. Predictions with stated probabilities ("I'm 70% sure this will happen by end of Q2") can be scored after the fact. The act of committing a number creates the data you'll need later.
Second, use the full range of confidence levels, including the extremes. If you're truly very sure, say 95%. If you're truly clueless, say 50%. Don't compress everything into 70–80%. The full range is required for the feedback to discriminate between genuinely confident and merely overconfident claims.
Third, make many predictions of varying difficulty. You can't calibrate yourself on five predictions a year. Aim for many: dozens at a minimum, ideally hundreds, across different domains and difficulty levels. Volume is what makes calibration measurable.
Fourth, review your record honestly when outcomes resolve. Don't rationalize wrong predictions ("technically I was right because…"). Don't claim you predicted things you didn't. The whole point of writing them down is to remove the hindsight bias that would otherwise destroy your ability to learn. Being uncomfortable with your record is part of the process.
Fifth, look for the patterns in your misses. After enough predictions, you'll see your characteristic failure modes. Maybe you're systematically overconfident about your own field, or systematically under-confident about geopolitics, or anchored too hard on first impressions. Each pattern is a specific lever you can adjust.
Two excellent low-friction tools exist for this: prediction-tracking apps and public prediction platforms. Apps like Manifold Markets, Metaculus, and PredictionBook let you log predictions, see them resolved, and track your calibration over time with formal scoring. Even informally, you can do this in a notes file or a spreadsheet. The important thing is that the predictions are timestamped, the confidence is explicit, and the record is honest.
Where calibration breaks down
Calibration is one of the most useful concepts in probabilistic thinking, but it has real limits. Pretending otherwise can lead to its own forms of error.
Domains with no feedback
Calibration depends on a feedback loop. You need to know how things turned out to assess whether your confidence was justified. In domains where outcomes never resolve clearly (long-horizon predictions, counterfactual claims, questions of interpretation), calibration cannot develop because the loop never closes. This is part of why pundits commenting on geopolitics, philosophers of mind, and theologians can be persistently miscalibrated without paying any cost, because the world doesn't tell them they were wrong, because the world doesn't tell anyone whether they were wrong on those questions.
Rare or unique events
Calibration is a property of repeated forecasts, but some of the most important questions in life are unique events that won't recur. Was your decision to take that job a 70% bet or a 30% bet? You'll never know. There's only one outcome, and your confidence in it can't be evaluated against a hit rate because no hit rate exists. For one-of-a-kind decisions, calibration training on similar repeated decisions can sharpen your judgment, but it can't directly score the unique case. This is a real limitation, and it's why calibration is most powerful in domains with structurally similar repeating questions.
Calibration is not the same as wisdom
You can be perfectly calibrated and still be wrong about almost everything important. If you're calibrated on trivial questions but uncalibrated about the questions that matter, the technical skill provides limited real-world benefit. Calibration is necessary but not sufficient for good judgment. The other necessary parts include: asking the right questions, having relevant knowledge, recognizing which questions are answerable in the first place, and noticing when you're being asked to forecast something that calibration training simply doesn't apply to. Calibration is a piece of the puzzle, not the whole puzzle.
The tyranny of measurable predictions
A subtle danger of calibration training is that it can over-emphasize predictions that are easy to score at the expense of judgments that aren't. The forecaster who only makes well-defined, time-bounded, binary predictions can become very calibrated on those, while losing the ability to reason about messier, more important questions that don't fit the format. The Goodhart's Law connection is direct: if you optimize for "calibration on measurable predictions," you may end up neglecting the larger judgments where measurability isn't possible. Good calibration practice involves humility about what calibration training does and does not improve.
How to actually use it
The discipline of calibration is about closing a loop most people never close: between the confidence you claim and the outcomes you actually get. Here's the working version of the framework, calibrated for real life rather than for forecasting tournaments.
The calibration discipline
Start writing your predictions down
Before you can improve calibration, you need data. Pick a notebook, an app, or a notes file, and start logging predictions whenever you make them. Include the date, the prediction, and a stated confidence level. Don't worry about format. Just create the substrate for feedback.
Use real probabilities, not vague hedges
Replace "probably" with a number. Replace "I'm pretty sure" with "70%." This is uncomfortable at first because it commits you to a position, which is exactly the point. Vague predictions can't be evaluated, and unevaluable predictions can't improve your calibration.
Use the full range of confidence levels
Force yourself to use 5%, 30%, 95%, and 50%, not just the comfortable 70–80% middle. If you're really uncertain, say 50% or 60%. That's a calibrated answer for a hard question. If you're really sure, say 95%, but only if you're willing to be wrong only 5% of the time at that level.
Review honestly, especially the wrong ones
When outcomes resolve, mark them as right or wrong without rationalizing. Look for the predictions you made at 90% confidence that turned out wrong. Those are the highest-value training data points, because the gap between claimed confidence and actual outcome is largest there.
Notice your characteristic patterns
After enough predictions, your specific miscalibration patterns will become visible. You might be overconfident in your professional domain and well-calibrated outside it, or vice versa. You might consistently anchor too high. Each pattern is a specific adjustment you can make over time.
Treat calibration as a long-game investment
Improvement is gradual and the early data is noisy. The first dozen predictions barely tell you anything. The first hundred start to reveal patterns. The first thousand make you measurably sharper than the average forecaster. Most people give up before the data becomes useful. Staying with the practice is most of the work.
Calibration is the audit on every other piece of probabilistic thinking. Bayes, base rates, and expected value all assume that your probabilities mean what they say they mean. Until you've checked, they probably don't.
The principle, restated
Confidence is a number that's supposed to match a frequency. When you say 70%, you're making a promise about your long-run hit rate at that confidence level. Most people break that promise constantly without realizing it, because they never collect the data that would let them notice. The discipline of calibration is the simple, slow process of starting to keep that promise, and the reward, accumulated over years, is becoming a person whose stated confidence can actually be trusted, including by yourself.
Philip Tetlock's twenty-year study of expert forecasting was, on the surface, a finding about the limits of expertise. But the deeper finding, the one tucked into the data on the small subset of forecasters who outperformed dramatically, was a finding about a learnable skill that almost no one is taught. Calibration is not innate. It is not a matter of intelligence. It is the result of a specific feedback loop, applied consistently over time, that trains a person to know how confident to be. The forecasters who have it become more accurate not because they know more facts but because their probabilities mean what they say they mean.
Most people will never train this skill, because the world doesn't directly reward calibration the way it rewards confidence. The pundit who says "this will definitely happen" is invited back on television; the analyst who says "I think there's a 60% chance" is told to be more decisive. The structural pressures push toward miscalibration, and most professionals respond to those pressures because they're the ones with consequences they can feel. Calibration's payoffs, by contrast, are diffuse and slow: better long-term decisions, deeper trust from people who pay attention to your record, and the rare quiet satisfaction of being right when you said you'd be right and humble when humility was warranted.
That's a small audience. But it's a meaningful one, and the people who develop genuine calibration end up doing disproportionately well in domains where being honest with yourself about what you know matters more than sounding sure of yourself in public. The skill won't make you famous. It will, if you keep at it, make you considerably better at thinking, which over a long enough horizon, is most of what makes anyone good at anything.